基于 Transformer 的多目标跟踪算法
1696 字
9 分钟

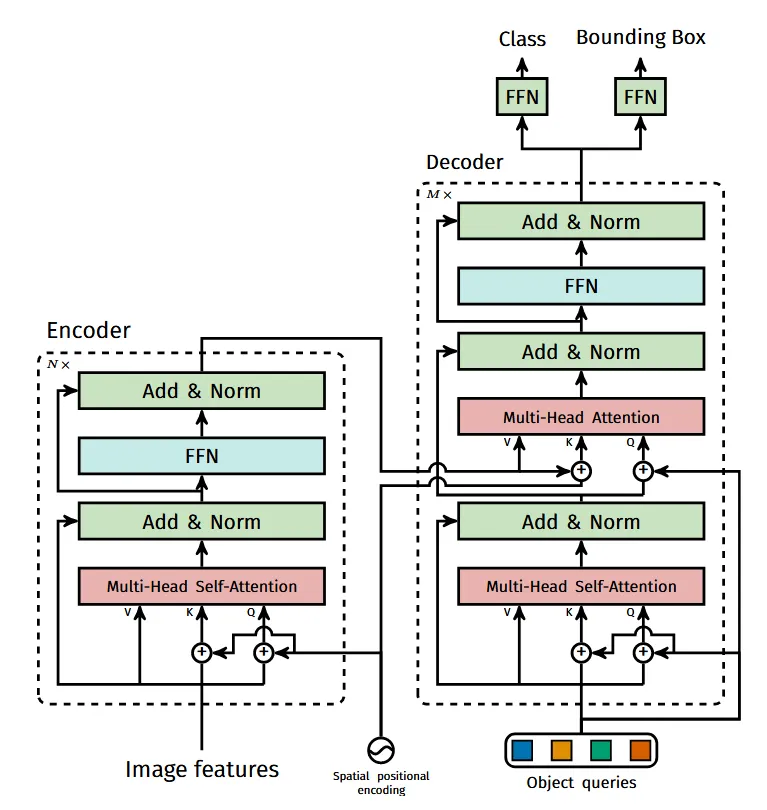
本文主要介绍TransTrack, TrackFormer, MORT三种算法,但考虑到三篇文章中都与 DETR 高度相关,这里对DETR也做一个简单的介绍。
DETR 通过解码器得到固定 N 个预测集(N设置的远大于实际图像中的目标数量)
import torchfrom torch import nnfrom torchvision.models import resnet50
class DETR(nn.Module):
def __init__(self, num_classes, hidden_dim, nheads, num_encoder_layers, num_decoder_layers): super().__init__() # We take only convolutional layers from ResNet-50 model self.backbone = nn.Sequential(*list(resnet50(pretrained=True).children())[:-2]) self.conv = nn.Conv2d(2048, hidden_dim, 1) self.transformer = nn.Transformer(hidden_dim, nheads, num_encoder_layers, num_decoder_layers) self.linear_class = nn.Linear(hidden_dim, num_classes + 1) self.linear_bbox = nn.Linear(hidden_dim, 4) self.query_pos = nn.Parameter(torch.rand(100, hidden_dim)) self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2)) self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
def forward(self, inputs): x = self.backbone(inputs) h = self.conv(x) H, W = h.shape[-2:] pos = torch.cat([ self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1), self.row_embed[:H].unsqueeze(1).repeat(1, W, 1), ], dim=-1).flatten(0, 1).unsqueeze(1) h = self.transformer(pos + h.flatten(2).permute(2, 0, 1), self.query_pos.unsqueeze(1)) return self.linear_class(h), self.linear_bbox(h).sigmoid()
detr = DETR(num_classes=91, hidden_dim=256, nheads=8, num_encoder_layers=6, num_decoder_layers=6)detr.eval()inputs = torch.randn(1, 3, 800, 1200)logits, bboxes = detr(inputs)目标查询:与传统方法中的锚框作用类似,但是这是一个可学习的参数,用于查询特定位置的目标框。 全连接层:编码器中的全连接层实际上由两层 的卷积层组成。
下面分别是基于检测的多目标跟踪、基于注意力机制的单目标跟踪、基于注意力机制的多目标跟踪流程。
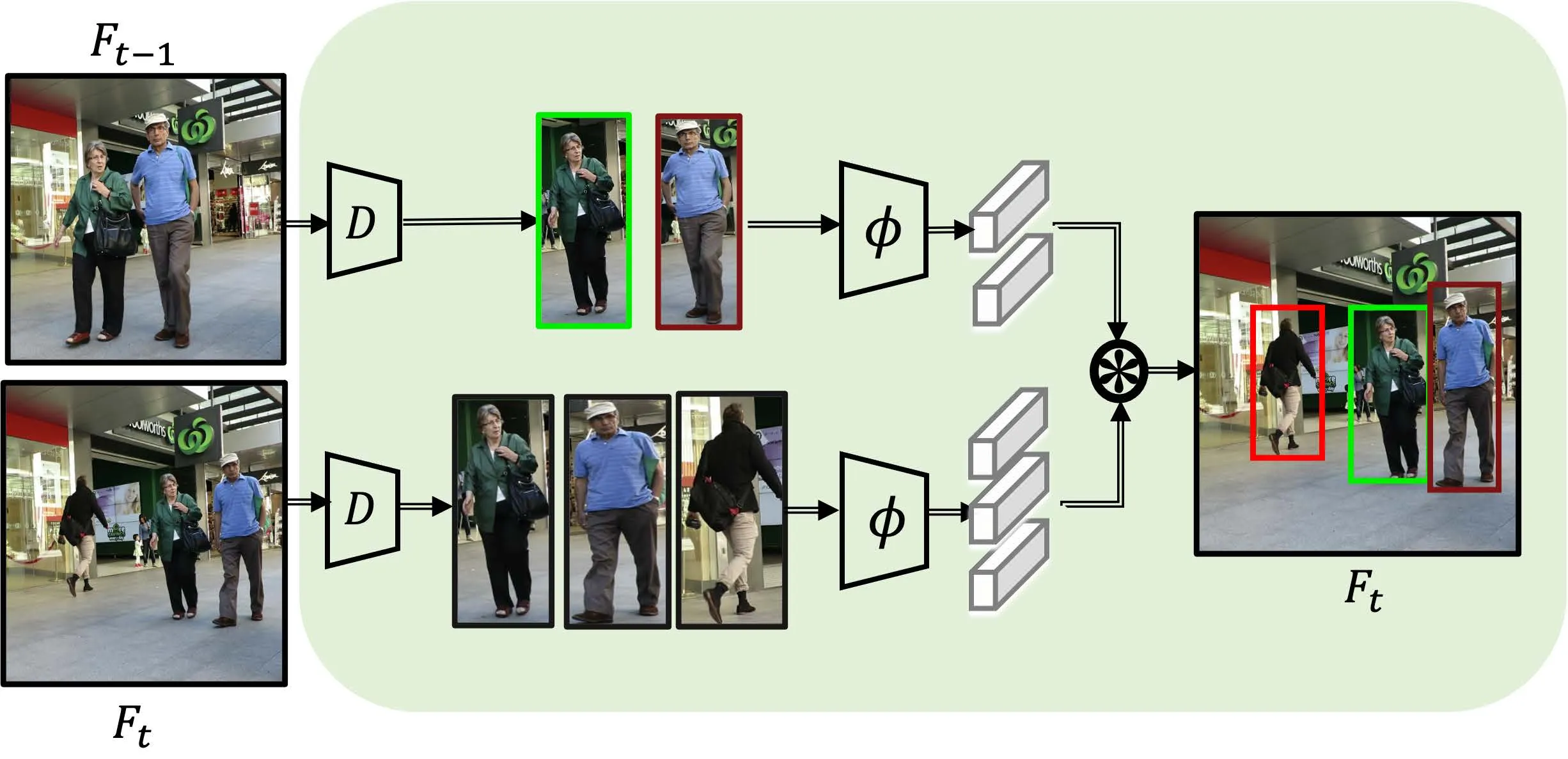
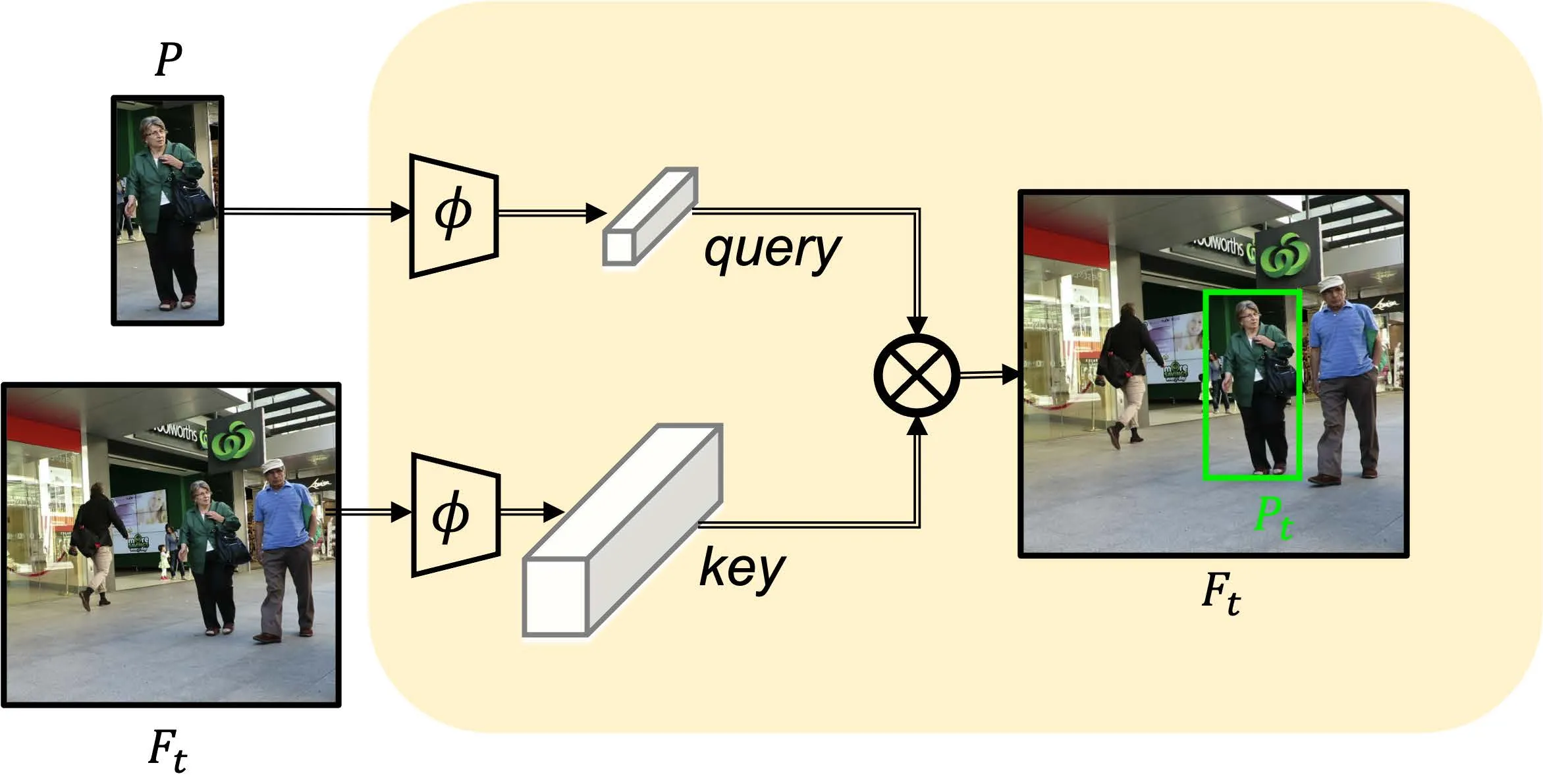
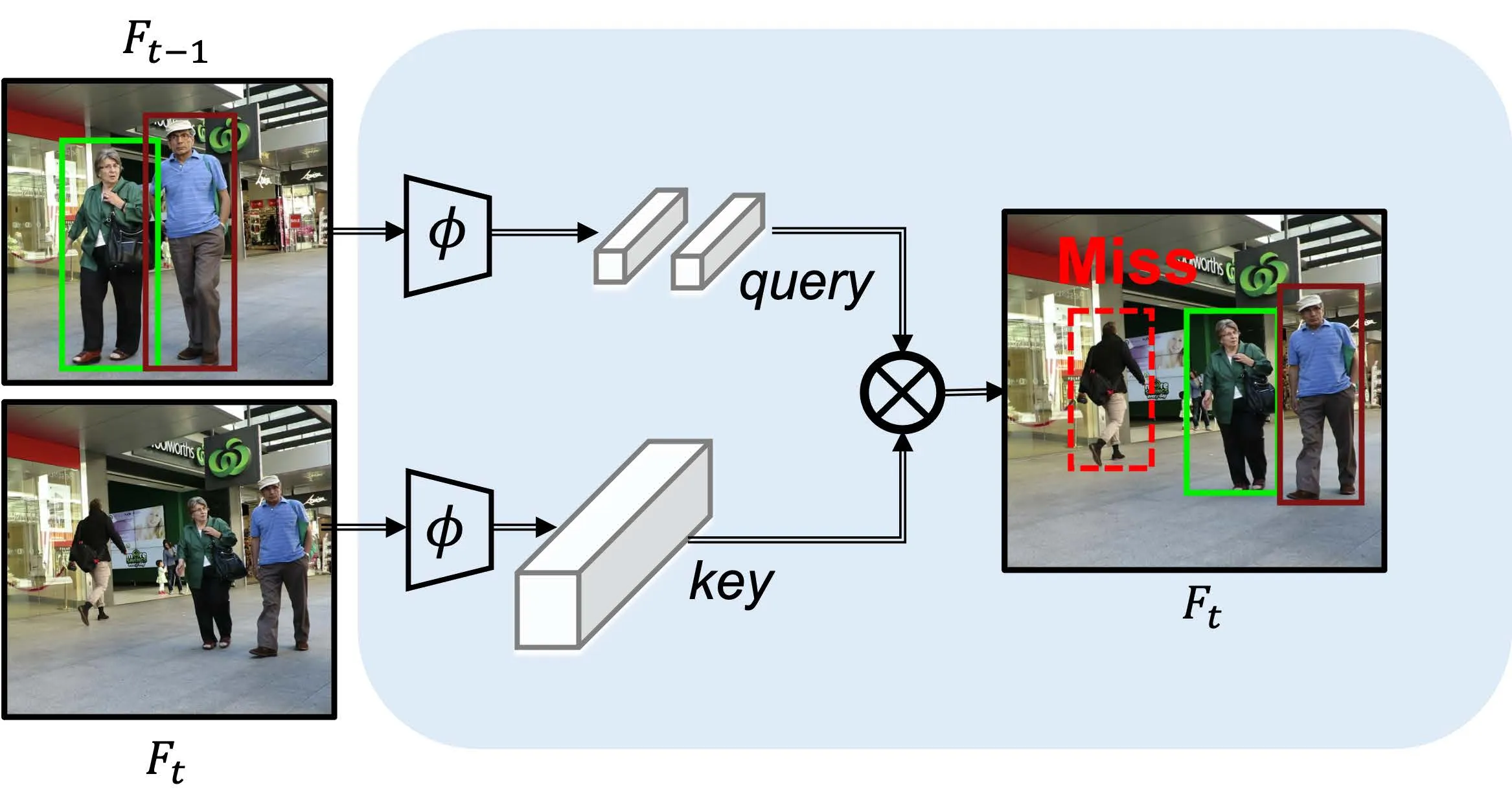
在单目标跟踪领域,注意力机制将上一帧的目标作为Query,下一帧作为Value,很容易就能实现对于单目标的跟踪。 但是对于多目标,这样的方法无法处理新生的目标,存在局限性。需要设计额外的流程来处理新生的轨迹。
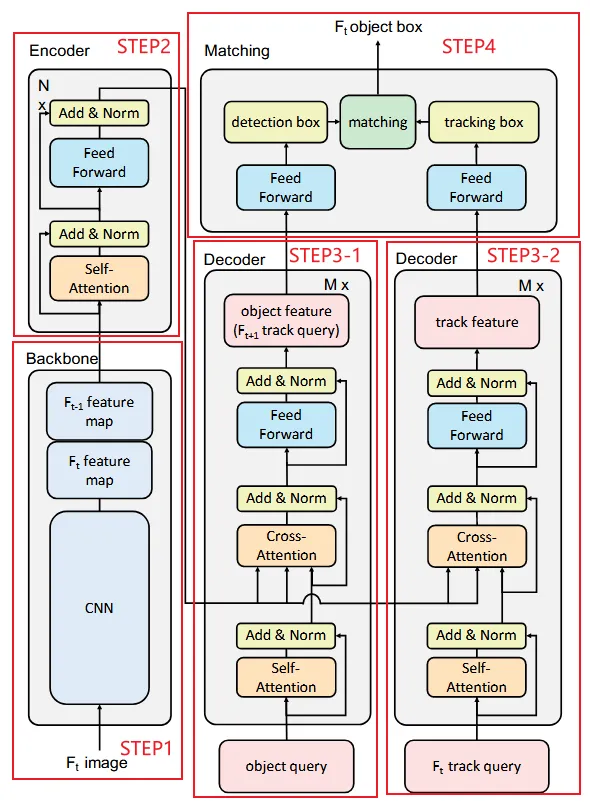
TIP实际上,可以将该过程视为分别从当前帧的检测框和通过上一帧轨迹得到的检测框,再进行IoU匹配,得到当前帧的跟踪结果。
其根本的思想与传统的TBD范式较为相似,可简单的将其理解为,使用 STEP3-2 中的代替了TBD中的卡尔曼滤波器的预测功能(但是预测的依据基于外观信息而非运动模型)。
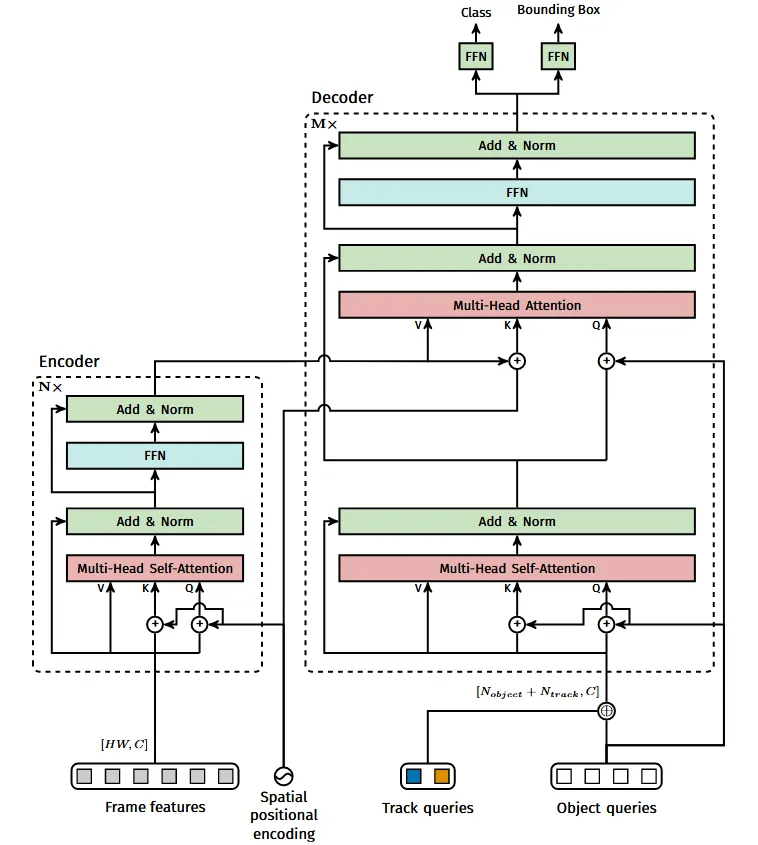
TIPTrackFormer的思路很简单,对比TrackFormer和DETR的网络结构,我们就能发现,二者的主要区别就是解码器的输入不同: DETR的输入为 Object Query,而TrackFormer就是在此基础上将 Object Query 和 Track Query 拼接起来。
在 DETR 的基础上设计,与同期的 TransTrack 和 TrackFormer 相比,无需非极大值抑制和IoU匹配的后处理。
在 DETR 中,使用的是固定长度的对象查询,检测可以分配给任意对象。
而 MOTR 中引入了轨迹块感知标签分配 (TALA) 使检测查询仅用于检测新生成的对象,跟踪查询预测跟踪对象,如下图所示。

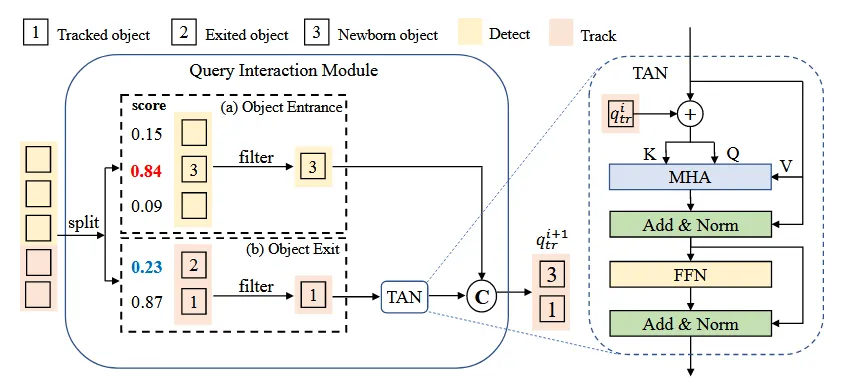 QIM 的输入是 Transformer 解码器产生的隐藏状态和对应的预测分数。在训练过程中,对于跟踪查询得到的对象,如果匹配的对象在真实值中消失或预测边界框与目标之间的交并比(IoU)低于0.5的阈值,则移除已终止对象的隐藏状态;对于对象查询的到的对象,只保留得分高于入门阈值的结果。
QIM 的输入是 Transformer 解码器产生的隐藏状态和对应的预测分数。在训练过程中,对于跟踪查询得到的对象,如果匹配的对象在真实值中消失或预测边界框与目标之间的交并比(IoU)低于0.5的阈值,则移除已终止对象的隐藏状态;对于对象查询的到的对象,只保留得分高于入门阈值的结果。
特别的,过滤后的对于跟踪查询得到的对象,通过时间聚合网络(TAN)后,与新生对象连接。
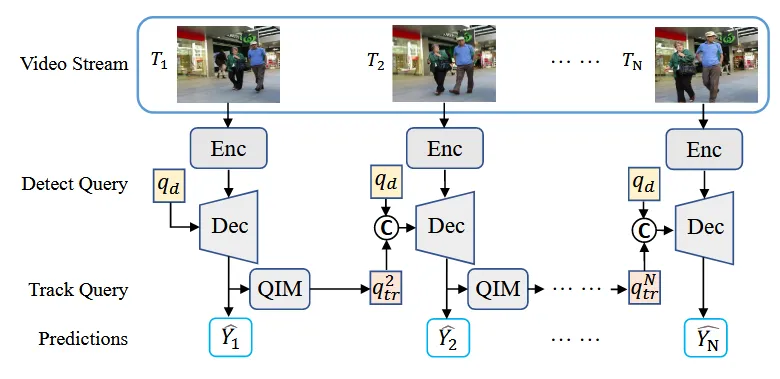
TIP跟踪查询集动态更新,初始化为空;检测查询用于查询新出现的对象。当前时刻跟踪查询和检测查询得到的所有跟踪框在下一时刻用于跟踪查询,而当前时刻已终止的跟踪对象将会从跟踪查询集中删除。
将检测查询和跟踪查询连接起来,输入到解码器中。在实践中,检测查询将只会检测新生成的对象,因为Transformer解码器中自注意力机制的查询交互将抑制检测跟踪对象的查询。
