YOLO
1115 字
6 分钟
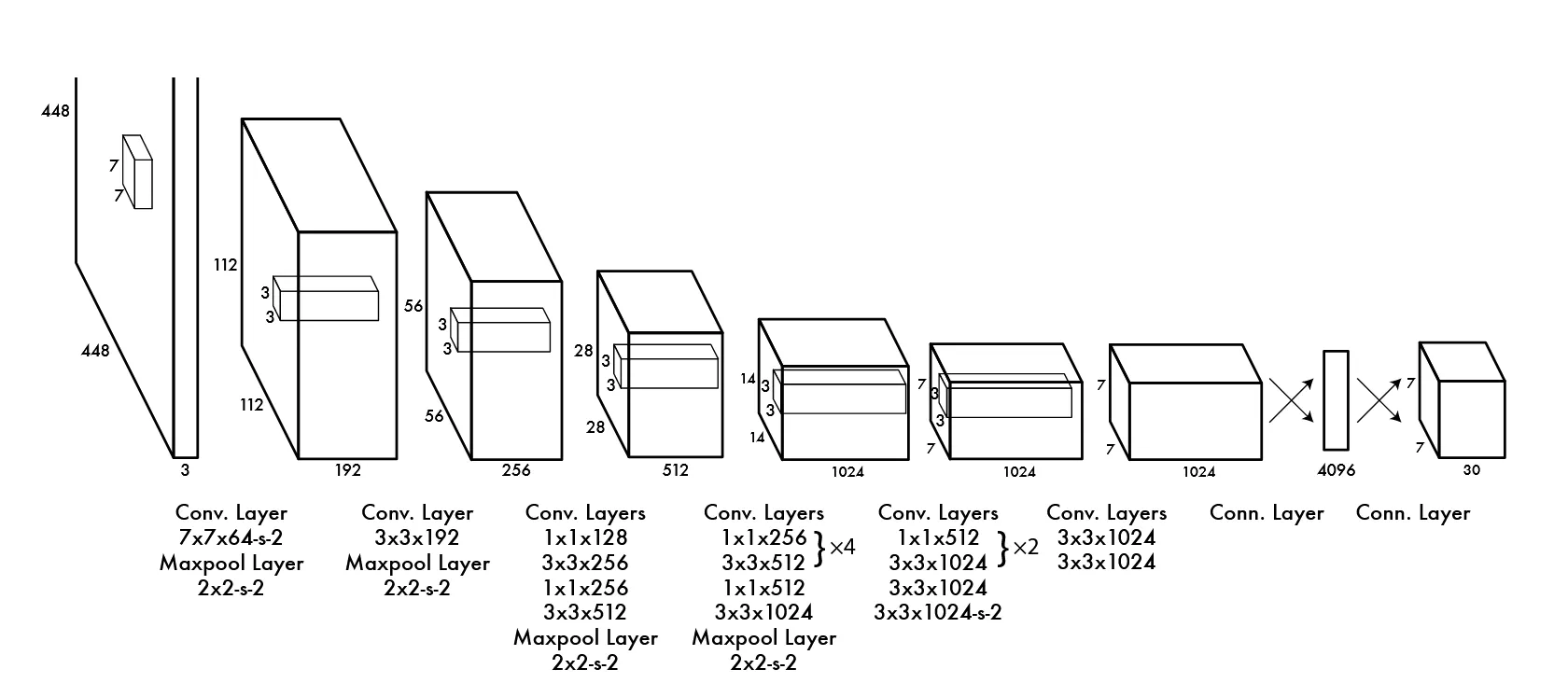
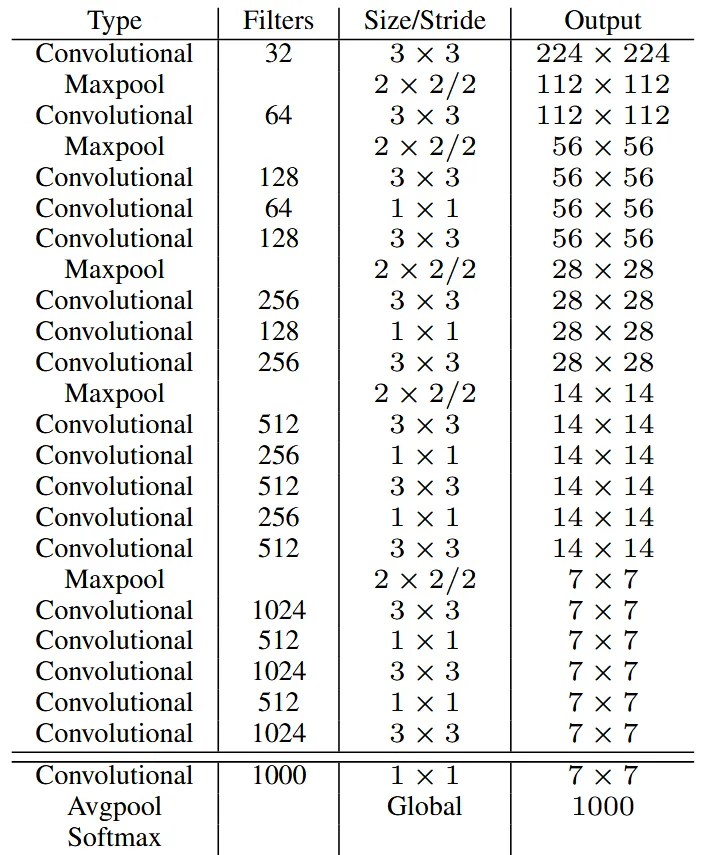
YOLOv2的基础是一个新的模型 Darknet-19 ,其结构如图:
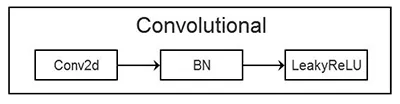
其中,Convolutional 层由卷积层、批量归一化、LeakyRelu 激活函数组成。
YOLO9000 的主要检测网络也是 YOLO v2,但其同时使用 WordTree 混合不同资源的数据集进行训练,能实时地检测超过9000种物体。
YOLO v3 使用了Darknet-53 作为基础网络,其使用了更多的卷积层,引入了残差连接,并去掉了中间的池化层。
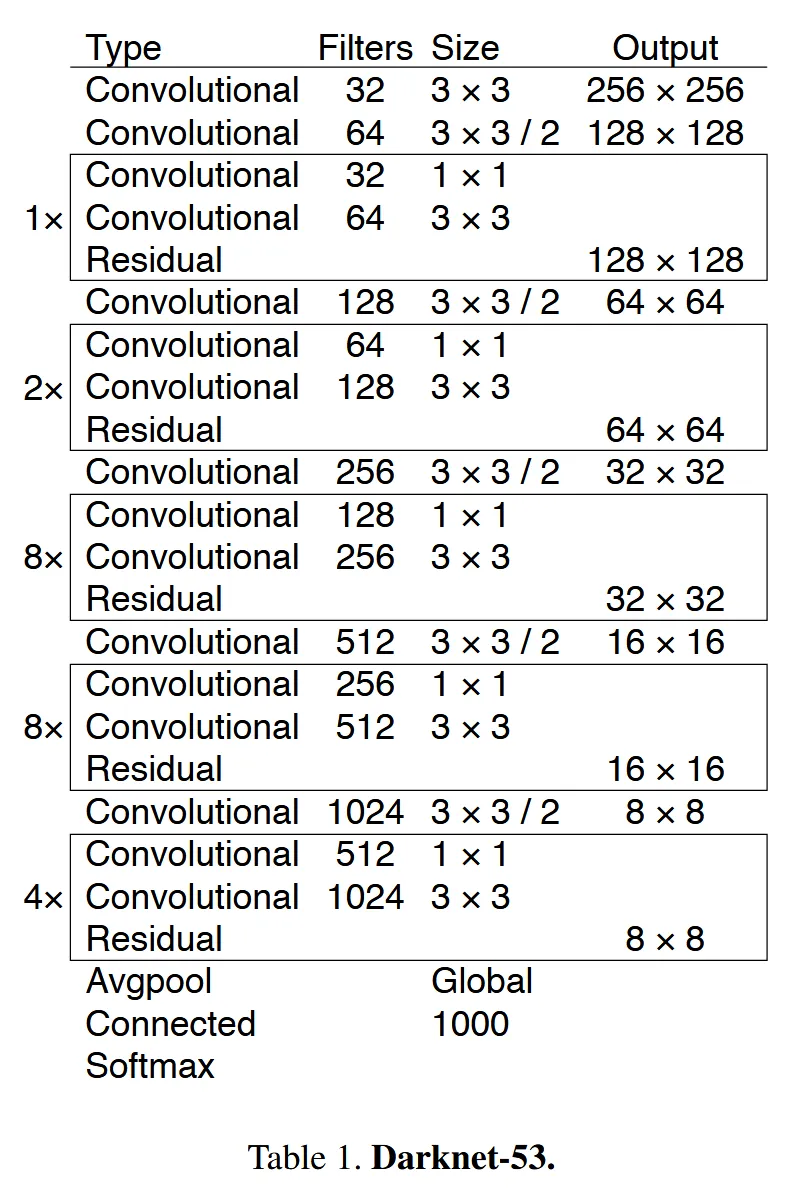
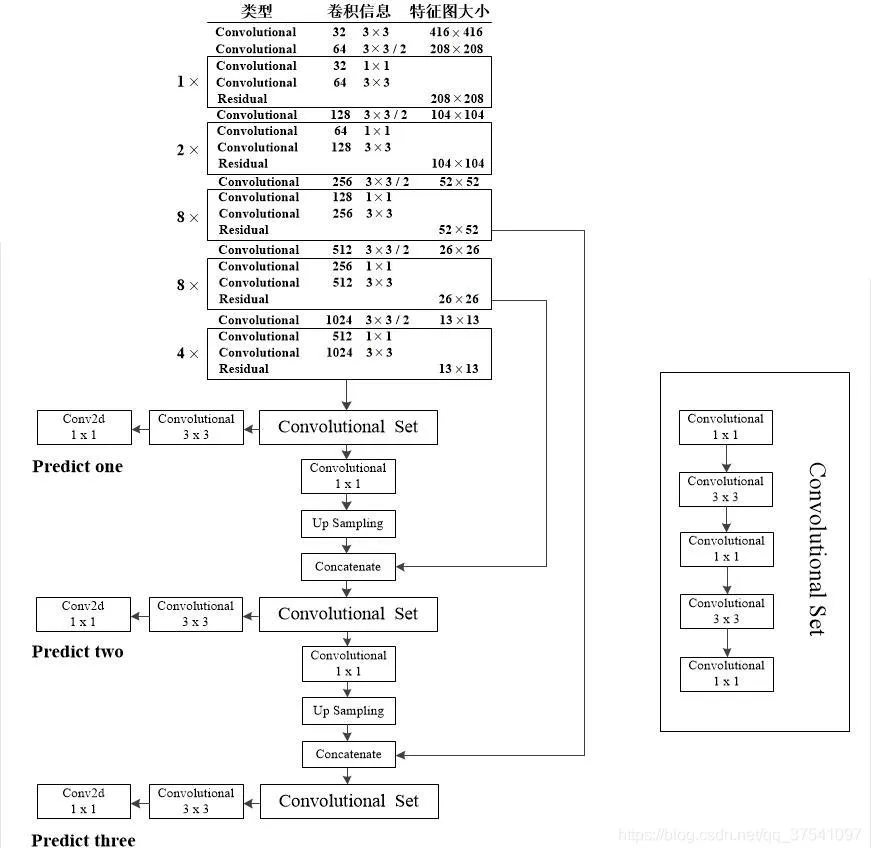
YOLO v3 利用三个不同尺寸的特征图来预测不同尺寸的目标。
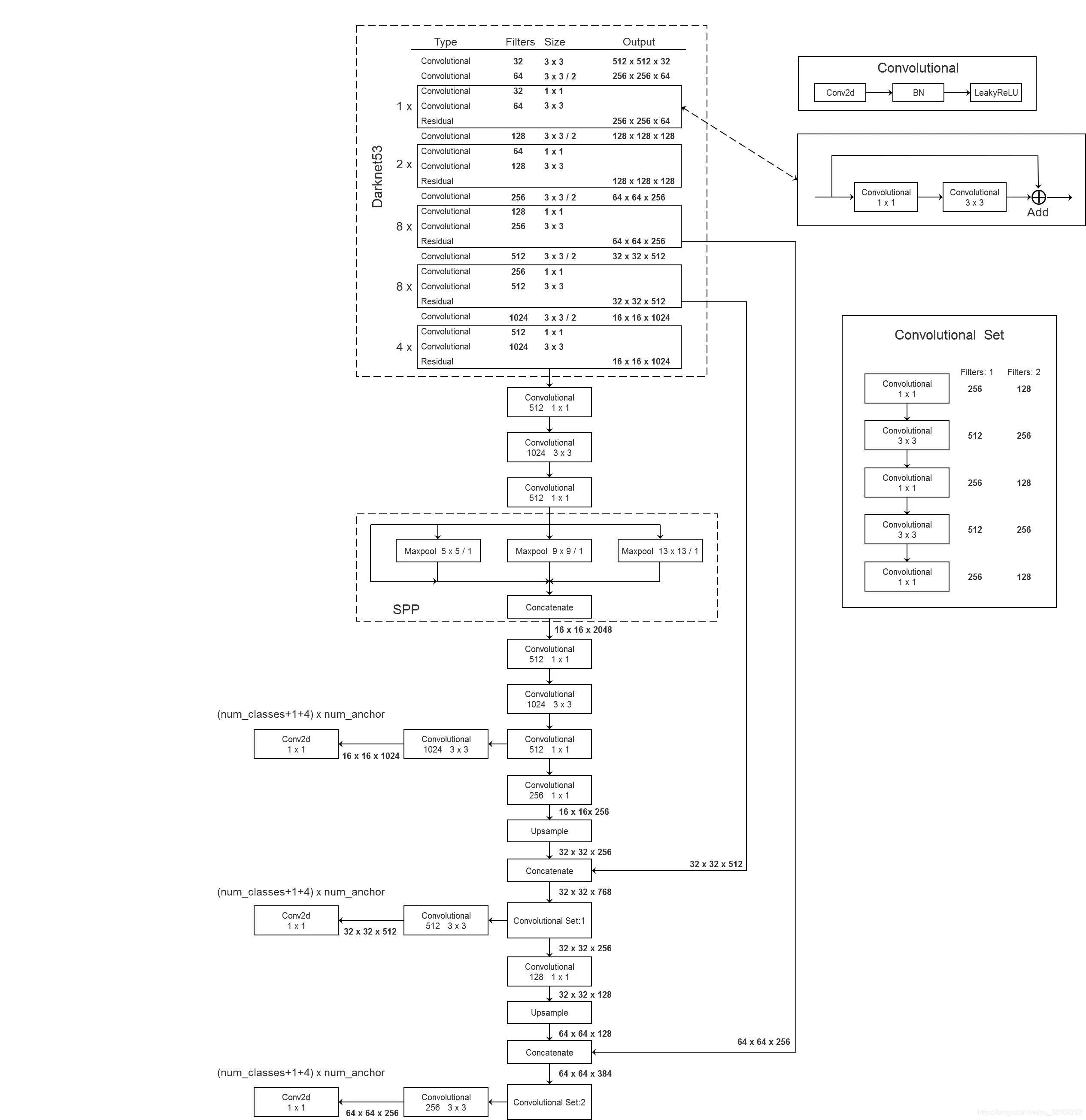
在使用 SSP 结构后的YOLO v3 网络结构如下:
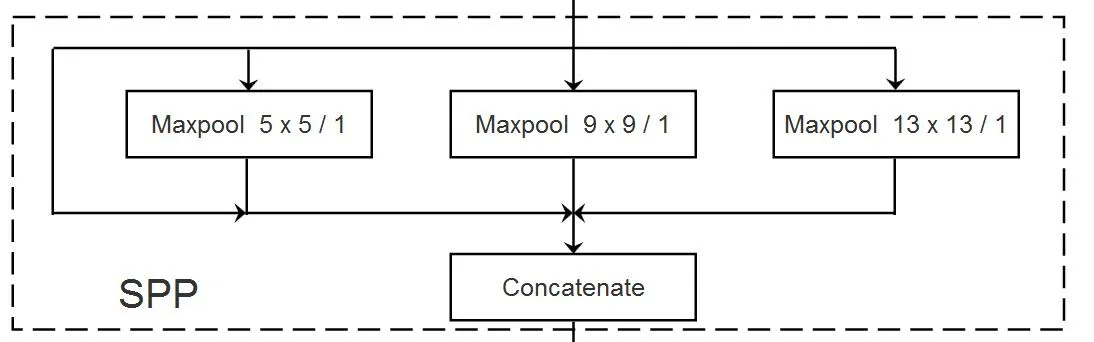
SPP(Spatial Pyramid Pooling) ,是 YOLO v3 中使用的一种结构,它可以将特征图进行不同尺寸的 池化 ,并生成多个特征图,从而获得更 Fine-Grained 的特征。
在目标检测中,L2 Loss不能很好的计算出目标框实际的好坏。在下图中,L2 Loss的结果相同,但是IOU相差很大。
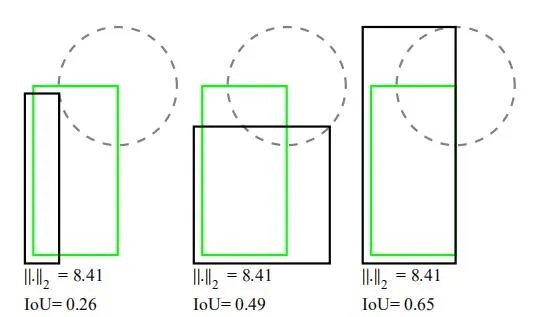
为了更好的衡量实际检测的IOU,引入IOU Loss:
但是IOU Loss在预测框和真实框相差较大时,始终等于0,梯度为0, 无法进行梯度下降。 为解决这一问题引入了GIoU(Generalized IOU) Loss。
GIoU也存在一些不足,如下图:
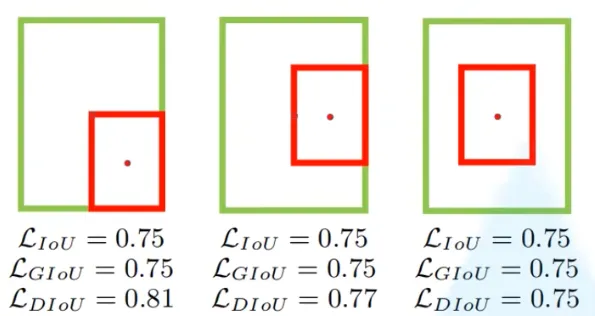 IoU和GIoU并不能判断出上面不同检测结果的好坏,实际上,这些方法的收敛速度也较慢。
IoU和GIoU并不能判断出上面不同检测结果的好坏,实际上,这些方法的收敛速度也较慢。
通过引入 DIoU (Distance IOU) 和 CIoU (Complete IOU) 来解决上述问题。
Distance IOU Loss:
Complete IOU Loss:
Focal Loss: